Aurora Serverless v2でpgvectorとpg_trgmのハイブリッド検索をAWSコンソール上で試してみた

AWSを使って検索系のシステムを作っていると、「意味的に近い文章を拾いたい」場面と、「サービス名やリソース名を正確に拾いたい」場面が混在するのではないでしょうか?
たとえば、社内のナレッジベースで「EC2のタイプ変更」と検索したとき、「EC2インスタンスタイプ変更手順」だけでなく、「EC2サイズ変更メモ」のような意味が近い文書も一緒にヒットしてくれたら便利ですよね。でも、単純なキーワード検索だと「タイプ変更」と「サイズ変更」は別の文字列なのでヒットしません。かといって意味検索だけだと、「EC2」というサービス名の一致を重視した検索が難しくなります。
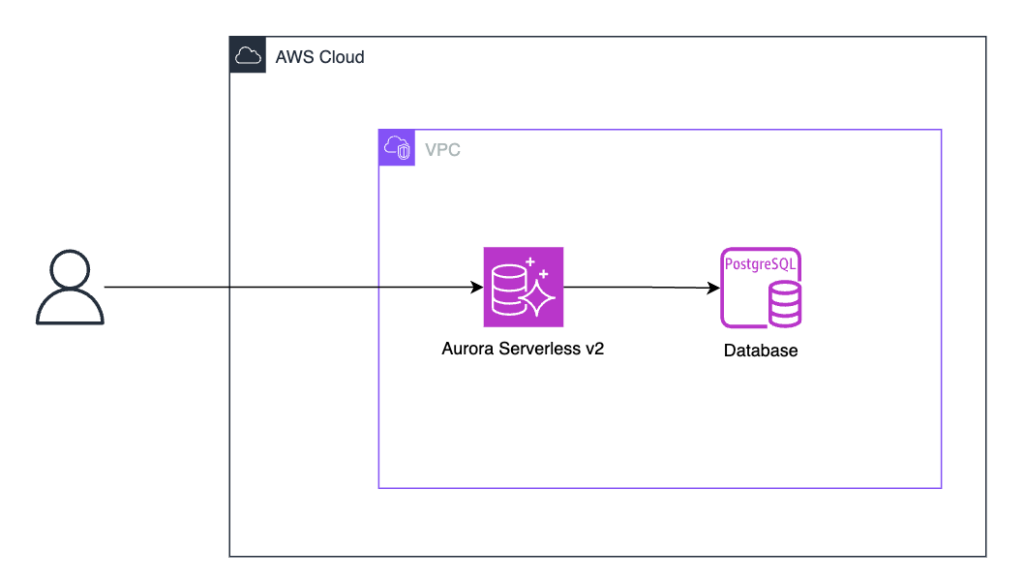
本ブログでは、この「意味的な検索」と「文字列的な検索」を組み合わせた 「ハイブリッド検索」 を、Aurora Serverless v2上で実際に試していきます。使うのはpgvector(ベクトル検索)とpg_trgm(文字列類似検索)という2つのPostgreSQL拡張機能です。
目次
Aurora Serverless v2 とは?
そもそもAmazon Auroraとは?
まず前提として、Amazon AuroraはAWSが提供するフルマネージドなリレーショナルデータベースサービスです。MySQLやPostgreSQLと互換性があります。「フルマネージド」というのは、サーバーのパッチ当てやバックアップなどの運用をAWSがやってくれるという意味です。
Aurora Serverless v2の特徴
Auroraには「プロビジョンド」と「Serverless」という2つのタイプがあります。プロビジョンドは、あらかじめ「このサイズのサーバーを使います」と固定で確保するタイプです。一方、Serverless v2はアクセス量に応じて自動的にスケールするタイプです。
もう少しかみくだいて説明すると、Auroraの性能はACU(Aurora Capacity Unit) という単位で決まります。ACUが大きいほどCPUやメモリが多く割り当てられ、処理能力が上がります。Serverless v2では、このACUが0.5単位で自動的に増減します。つまり、アクセスが少ない時間帯はコストを抑え、忙しい時間帯は自動でスケールアップしてくれるわけです。
検索システムのように、「普段は軽いアクセスしかないのに、特定の時間帯だけ急に検索が増える」といったワークロードにはぴったりの構成です。プロビジョンド構成では、ピーク時に合わせて大きめのサイズを確保し、その結果としてオフピーク時の余剰コストも受け入れなければならない、という悩みが生じがちですが、Aurora Serverless v2ではその負担を軽減できます。
また、条件を満たすエンジンバージョンでは0ACUまで下げるauto-pauseも利用できるため、開発環境のように常時アクセスがない環境ではコストをほぼゼロにできます。reader を使った水平スケールや、プロビジョンド構成との混在も可能です。
今回は性能ベンチマークを目的にはせず、まずは「Aurora Serverless v2をハイブリッド検索の基盤として素直に使えるか」を確認していきます。
pgvectorとpg_trgmを組み合わせる理由
pgvectorとは?(ベクトル検索)
pgvectorは、PostgreSQLでベクトル類似検索を行うための拡張機能です。
「ベクトル検索」というのは、文章を数値の並び(ベクトル)に変換して、その数値の近さで「意味的に似ている文章」を見つける仕組みです。たとえば、「インスタンスタイプ変更」と「サイズ変更」は文字列としては別物ですが、意味としては似ていますよね。ベクトル検索なら、このような「意味の近さ」を捕えられます。
ベクトルへの変換には、OpenAIのEmbeddings APIやAmazon BedrockなどのAIモデルを使います。今回は説明を簡単にするため、あらかじめ用意したベクトルをそのままデータベースに入れます。
pgvectorでは、高速に近いベクトルを探すためのインデックスとしてHNSWやIVFFlat が使えます。今回はより高速で精度が良いとされるHNSWを使います。「インデックス」というのは、本の索引のようなもので、検索を速くするための仕組みです。
pg_trgmとは?(文字列類似検索)
pg_trgmは、文字列をtrigram(3文字ずつの組み合わせ)に分解して類似度を求める拡張機能です。
たとえば、「EC2」という文字列は「E」「EC2」「C2」のように3文字ずつに分解されます。このtrigramの重なり具合で「文字列としてどれくらい似ているか」を判定します。完全一致でなくても、部分的に近い文字列を拾えるのが特徴です。
pg_trgmにはsimilarity()という関数があり、類似度を0〜1の数値で返してくれます(1に近いほど似ている)。また、%演算子を使うと、一定の類似度を超えたデータだけをフィルタリングできます。サービス名の記載揺れや、少し崩れた検索語への耐性を持たせたい場合に便利です。
pg_trgm用のインデックスにはGINインデックスを使います。GINは「この単語が含まれる行はどれか」を素早く絞り込めるタイプのインデックスで、テキスト検索と相性が良いです。
なぜ組み合わせるのか?
pgvectorは「意味的な近さ」に強い反面、略語や固有名詞の正確な一致は苦手です。逆に pg_trgmは「文字列の近さ」に強いけれど、意味的な言い換えは拾えません。
そこで、両方のスコアを組み合わせることで、それぞれの弱点を補い合えるのが「ハイブリッド検索」のアイデアです。なお、Aurora PostgreSQLのサポート拡張一覧でもpgvector/pg_trgmはどちらもサポート対象として記載されています。
今回の検証構成
今回の検証構成はできるだけシンプルにしました。Aurora PostgreSQL互換のAurora Serverless v2クラスターを1つ用意し、その中に検索対象のテーブルを作成します。アプリケーション部分は作らず、SQLで直接検索の挙動を確認していきます。
データとしては、運用手順書やナレッジメモを想定した短い文章を5件投入し、以下の3パターンで検索結果を比較しました。
- pgvectorによる意味検索 … ベクトルの近さだけでランキング
- pg_trgmによる文字列類似検索 … 文字列の近さだけでランキング
- ハイブリッド検索 … 両方のスコアを重み付き合算してランキング
なお、埋め込みベクトルはあらかじめ用意したものを投入しています。実際のプロダクションではOpenAI Embeddings APIやAmazon Bedrock等でベクトルを生成してください。また、ベクトルの次元数も今回は説明用に4次元にしていますが、本番ではモデルに合わせた次元数に変更してください(例: OpenAI text-embedding-3-small = 1536次元)。
環境構築
それでは、AWS マネジメントコンソールからAurora Serverless v2クラスターを作成していきましょう!
Aurora and RDSダッシュボードを開く
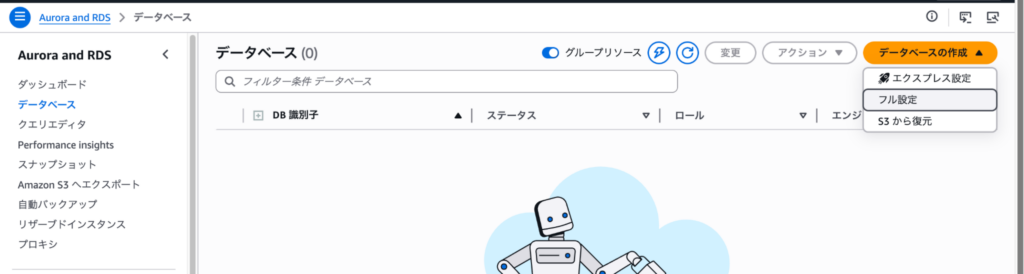
AWS マネジメントコンソールにログインしたら、上部の検索バーに「Aurora and RDS」と入力してダッシュボードを開きます。左メニューの「データベース」を選び、「データベースの作成>フル設定」ボタンをクリックします。
エンジンを選択
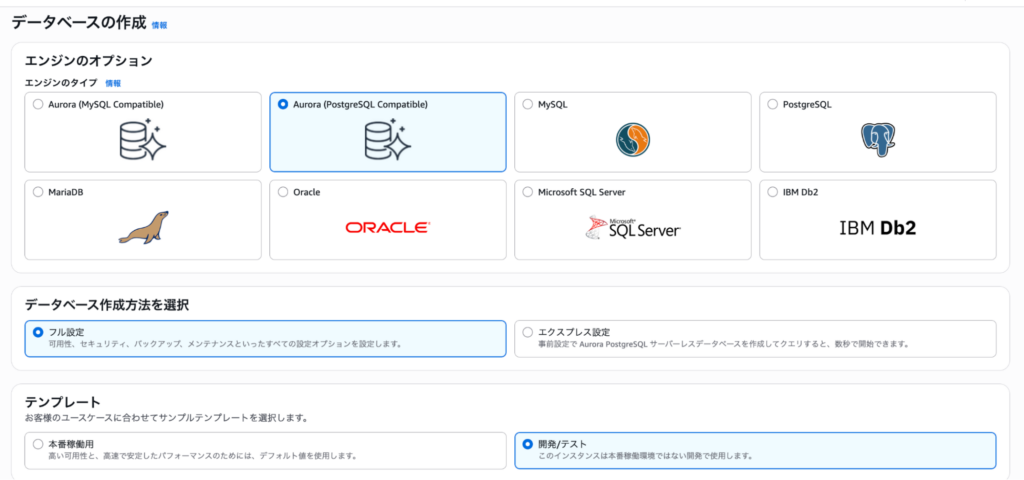
エンジンはAurora (PostgreSQL Compatible) を選択します。AuroraにはMySQL互換と PostgreSQL互換がありますが、pgvectorとpg_trgmはPostgreSQLの拡張機能なので、必ず PostgreSQL互換を選んでください。
テンプレートは検証目的なので「開発/テスト」を選びました。
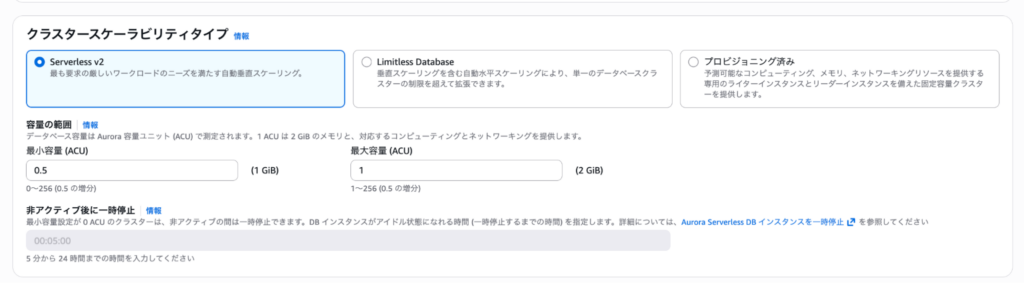
Serverless v2を有効にする
「クラスタースケーラビリティタイプ」の箇所でServerless v2を選択します。ここで「最小 ACU」と「最大 ACU」を設定できます。検証用なので、最小ACUは0.5、最大ACUは1と小さく設定しました。これで課金を抑えつつ検証できます。
「最小 ACU」が0.5というのは、アクセスがほぼなくても最低限の性能を確保するという意味です。「最大 ACU」は負荷がかかったときにどこまでスケールするかの上限です。本番では想定される負荷に合わせて適切に設定してください。
エンジンバージョンは、pgvectorがサポートされたものを選びます。以下AWSドキュメントでサポート対象のバージョンを確認できます。今回はAurora PostgreSQL 17を選択しました。
Amazon Aurora PostgreSQL の拡張機能バージョン
接続設定
マスターユーザー名とパスワードを設定します。これがデータベースに接続する際の認証情報になるので、忘れないようにメモしておきましょう。初期データベース名も入力し、VPCやセキュリティグループなど各種設定を完了させます。RDS Data APIの有効化もお忘れなく。
クラスター作成完了を確認
設定が完了したら「データベースの作成」ボタンをクリックします。作成には数分かかるので、ステータスが「利用可能」になるまで待ちましょう。ステータスは「作成中」→「利用可能」の順に変わります。
DBへの接続確認
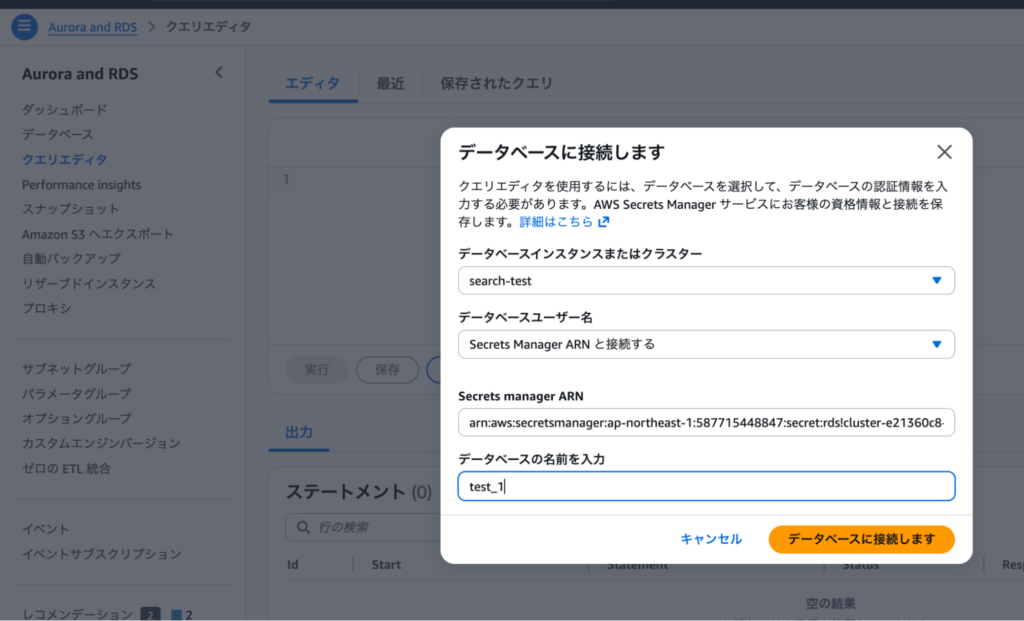
psqlまたはRDS Query Editorで接続します。RDS Query Editorはマネジメントコンソール上からブラウザだけでSQLを実行できるので、psqlの環境構築が不要でお手軽です。
左側メニューの「クエリエディタ」を選択すると以下の画面が開くので、各項目を入力してデータベースに接続します。
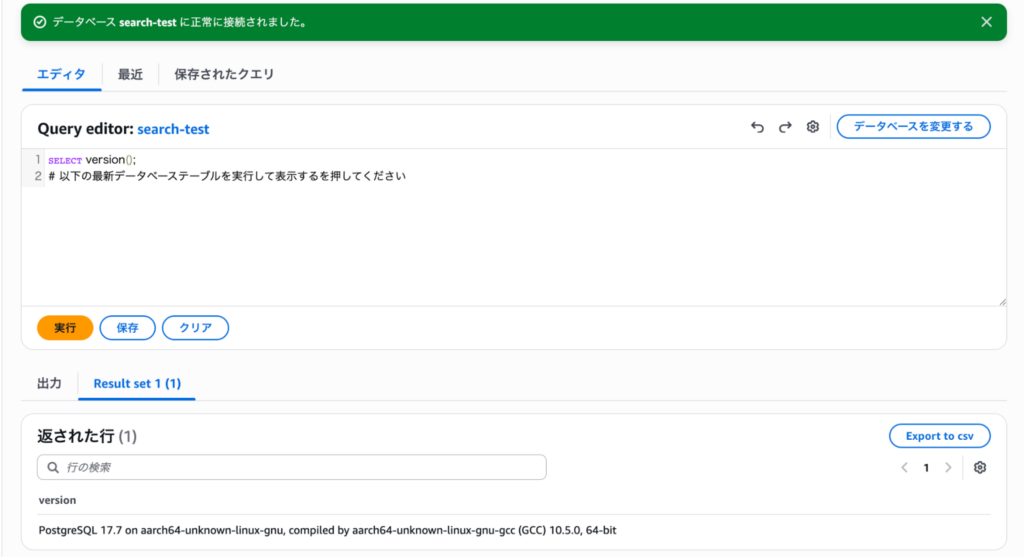
データベースに接続できたら、まずは以下のSQLを実行してバージョンを確認しましょう。「PostgreSQL xx.x」のような応答が返ってくれば接続成功です。
SELECT version();
テーブル作成と拡張機能の有効化
拡張機能の有効化
PostgreSQLには「拡張機能(Extension)」という仕組みがあり、標準にはない機能を後から追加できます。今回はpgvectorとpg_trgmという2つの拡張機能を有効化します。
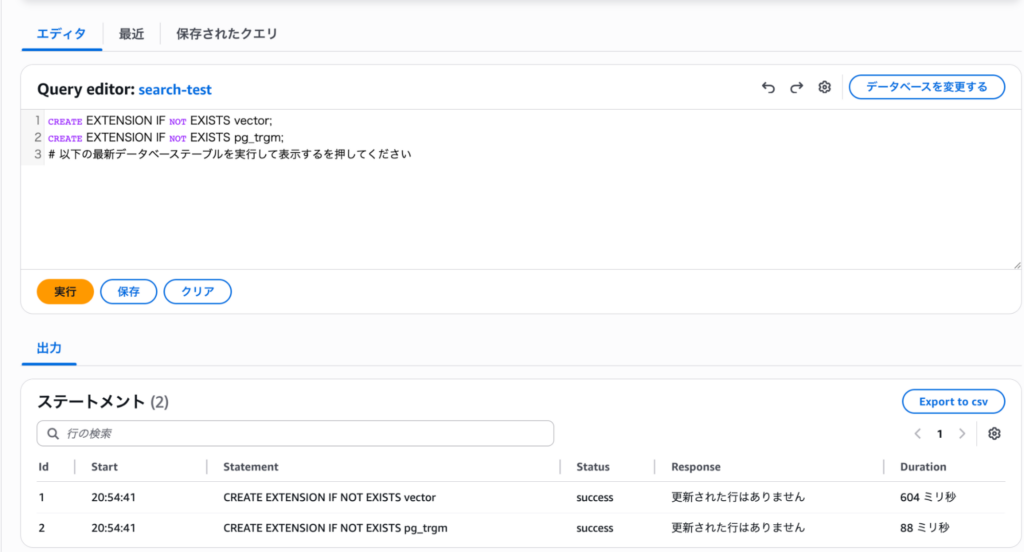
CREATE EXTENSIONコマンドで有効化します。IF NOT EXISTSを付けておくと、すでに有効化されている場合でもエラーになりません。
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS pg_trgm;
「CREATE EXTENSION」と表示されれば成功です。
検索対象テーブルの作成
次に、検索対象のデータを入れるテーブルを作ります。
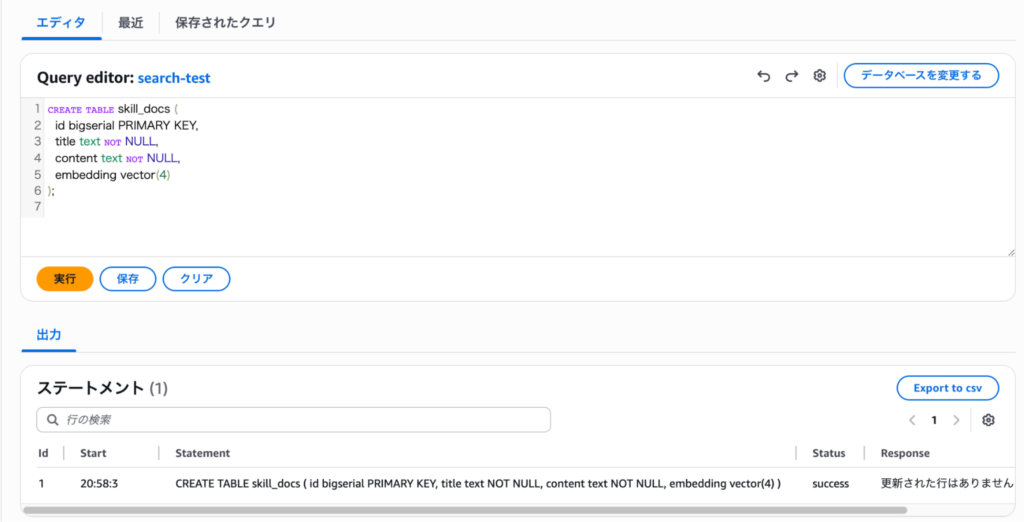
CREATE TABLE skill_docs (
id bigserial PRIMARY KEY,
title text NOT NULL,
content text NOT NULL,
embedding vector(4)
);
各カラムの意味を説明します。idはデータを一意に識別する番号で、bigserialを使うと自動で連番が振られます。titleは手順書のタイトル、contentは本文です。embeddingがpgvector 用のベクトルカラムで、vector(4) は「4次元のベクトルを格納する」という意味です。本番ではモデルに合わせた次元数に変更してください(例: OpenAI text-embedding-3-small なら vector(1536))。
インデックスの作成
インデックスは「本の索引」のようなもので、検索を高速化するために作成します。インデックスがなくても検索自体はできますが、データが増えると動作が遅くなるので、本番では必ず作成しましょう。
pgvector用にはHNSWインデックスを作成します。HNSWは「Hierarchical Navigable Small World」の略で、ベクトルの近傍検索を高速に行うためのアルゴリズムです。vector_cosine_opsは「コサイン類似度」で検索するという意味で、ベクトル検索では最もよく使われる方式です。
pg_trgm用にはGINインデックスをtitleとcontentそれぞれに作成します。gin_trgm_opsは「trigramを使った類似検索用のインデックス」という意味です。
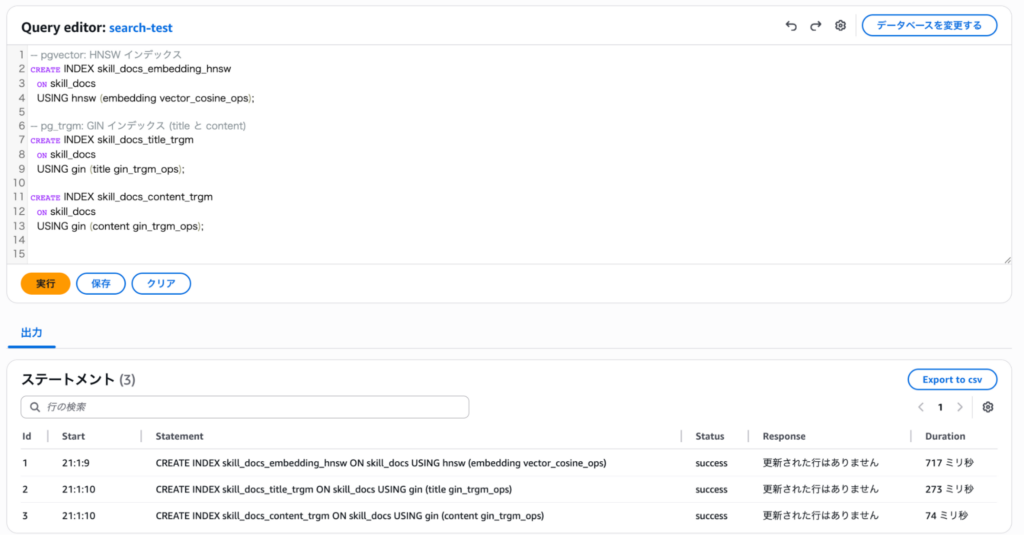
-- pgvector: HNSW インデックス
CREATE INDEX skill_docs_embedding_hnsw
ON skill_docs
USING hnsw (embedding vector_cosine_ops);
-- pg_trgm: GIN インデックス (title と content)
CREATE INDEX skill_docs_title_trgm
ON skill_docs
USING gin (title gin_trgm_ops);
CREATE INDEX skill_docs_content_trgm
ON skill_docs
USING gin (content gin_trgm_ops);
サンプルデータの投入
運用手順書やナレッジメモを想定したテストデータを5件登録します。ここがポイントなのですが、「意味的に似ているデータ」と「文字列として似ているデータ」が混ざるようにしています。後ほどの検索テストで違いが分かりやすくなります。
具体的には、「EC2 インスタンスタイプ変更手順」と「EC2 サイズ変更メモ」は意味的には似ていますが、文字列としては別物です。逆に、「EC2 インスタンスタイプ変更手順」と「EC2 タイプ変更」という検索語は、文字列としては部分的に一致しています。この違いが、後ほどの検索結果ではっきり見えてきます。
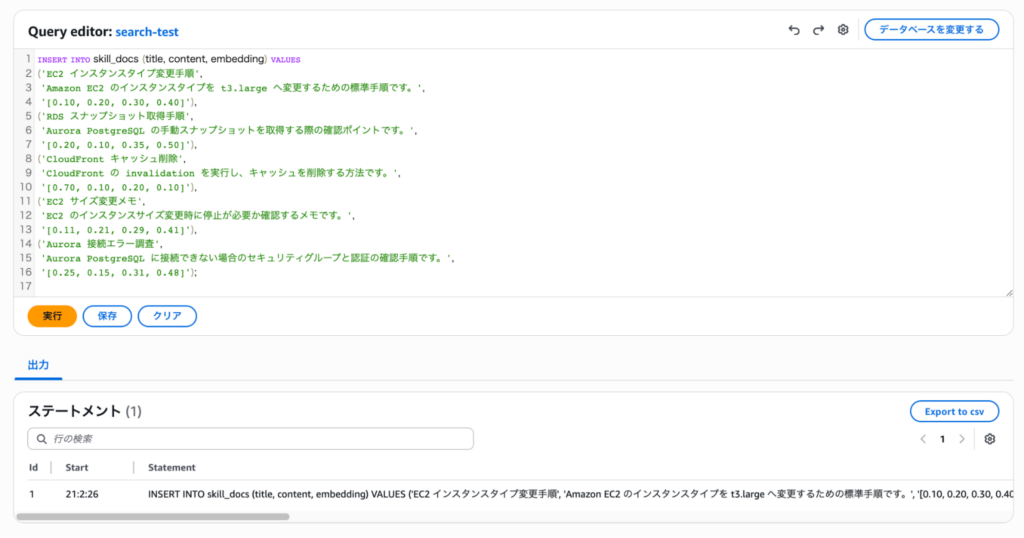
INSERT INTO skill_docs (title, content, embedding) VALUES
('EC2 インスタンスタイプ変更手順',
'Amazon EC2 のインスタンスタイプを t3.large へ変更するための標準手順です。',
'[0.10, 0.20, 0.30, 0.40]'),
('RDS スナップショット取得手順',
'Aurora PostgreSQL の手動スナップショットを取得する際の確認ポイントです。',
'[0.20, 0.10, 0.35, 0.50]'),
('CloudFront キャッシュ削除',
'CloudFront の invalidation を実行し、キャッシュを削除する方法です。',
'[0.70, 0.10, 0.20, 0.10]'),
('EC2 サイズ変更メモ',
'EC2 のインスタンスサイズ変更時に停止が必要か確認するメモです。',
'[0.11, 0.21, 0.29, 0.41]'),
('Aurora 接続エラー調査',
'Aurora PostgreSQL に接続できない場合のセキュリティグループと認証の確認手順です。',
'[0.25, 0.15, 0.31, 0.48]');
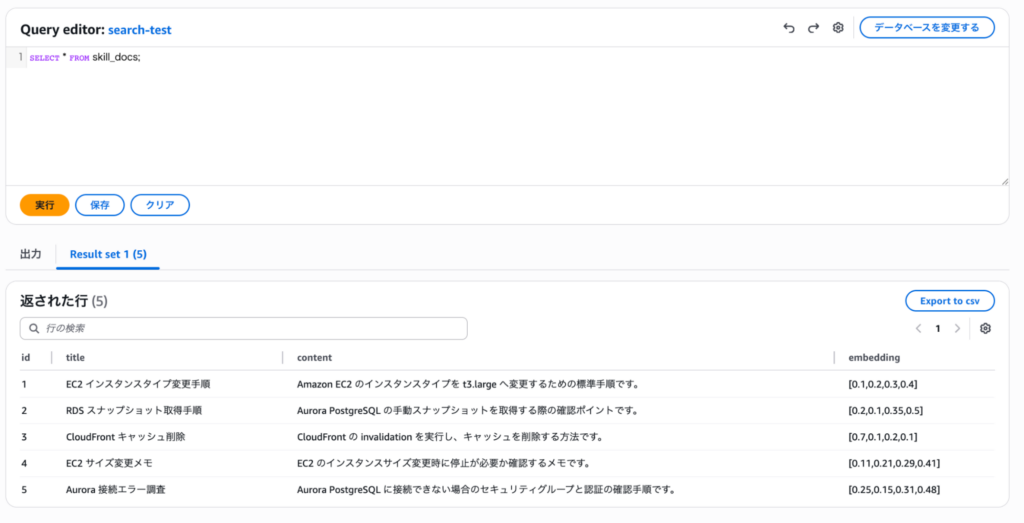
登録したデータを確認しておきましょう。以下のSQLで全件取得できます。
SELECT * FROM skill_docs;
ベクトル検索だけを試す
まずはpgvectorだけを使って検索してみましょう。
SELECT
id,
title,
1 - (embedding <=> '[0.10, 0.20, 0.30, 0.39]'::vector) AS score
FROM skill_docs
ORDER BY embedding <=> '[0.10, 0.20, 0.30, 0.39]'::vector
LIMIT 5;
このSQLを少し解説します。<=> はpgvectorが提供する「コサイン距離」を求める演算子です。コサイン距離は0〜2の範囲で、値が小さいほど似ています。1 - コサイン距離とすることで、「1 に近いほど似ている」という分かりやすいスコアに変換しています。
'[0.10, 0.20, 0.30, 0.39]'::vector は、検索クエリをベクトルで表現したものです。実際のプロダクションでは、ユーザーが入力した検索文をEmbeddings APIでベクトルに変換し、それをここに渡します。今回は「EC2 インスタンスタイプ変更手順」のベクトルに近い値を手動で指定しています。
ORDER BY ... LIMIT 5 で、類似度が高い順に上位5件を取得しています。
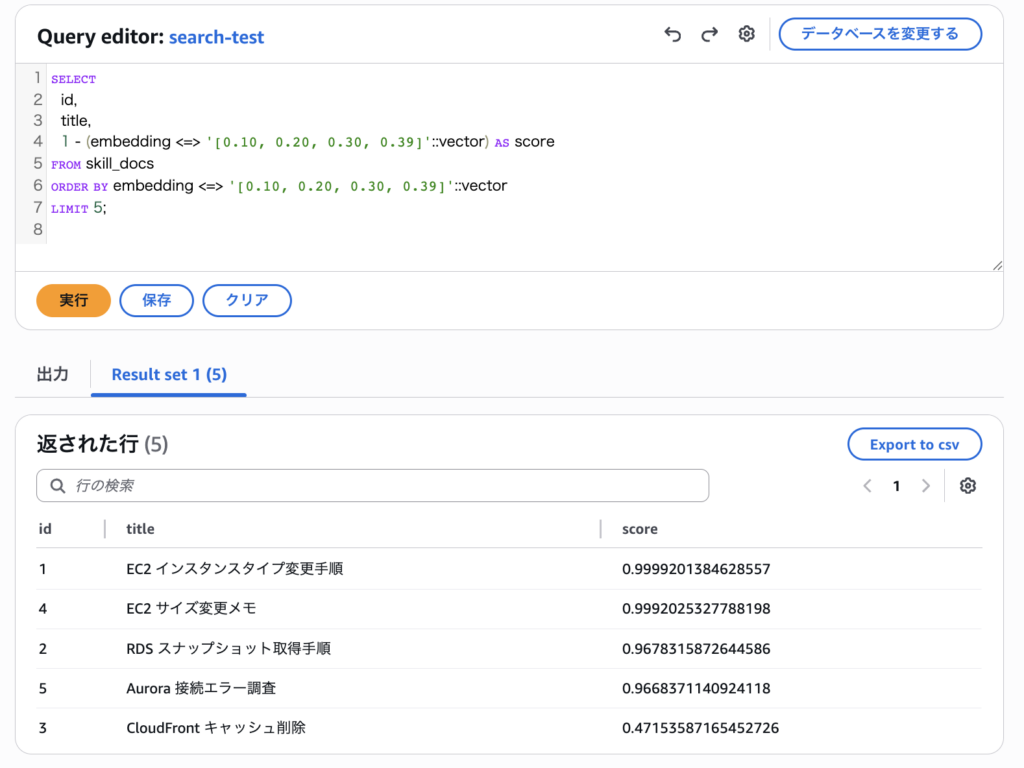
このクエリでは、「EC2 インスタンスタイプ変更手順」と「EC2 サイズ変更メモ」が上位に来ました。文字列は完全一致していませんが、意味的に近い内容を拾えています。これがベクトル検索の強みです。
一方で、略語や固有名詞の厳密な拾い方はコントロールしにくい印象でした。たとえば「EC2」というサービス名を含む結果を優先的に上に持ってくるといった制御は、ベクトル検索だけでは難しいです。
pg_trgm だけを試す
次に pg_trgm だけで検索してみます。
SELECT
id,
title,
similarity(title, 'EC2 タイプ変更') AS score
FROM skill_docs
WHERE title % 'EC2 タイプ変更'
ORDER BY score DESC
LIMIT 5;
このSQLも解説します。similarity(title, 'EC2 タイプ変更') は、titleカラムの値と検索語「EC2 タイプ変更」の文字列類似度を0〜1で返します。1に近いほど似ています。
WHERE title % 'EC2 タイプ変更' の % は pg_trgmが提供する「類似検索演算子」です。デフォルトでは類似度0.3以上のデータだけをフィルタリングしてくれます。つまり、あまりにもかけ離れた文字列は除外されるので、ノイズが混ざりにくくなります。
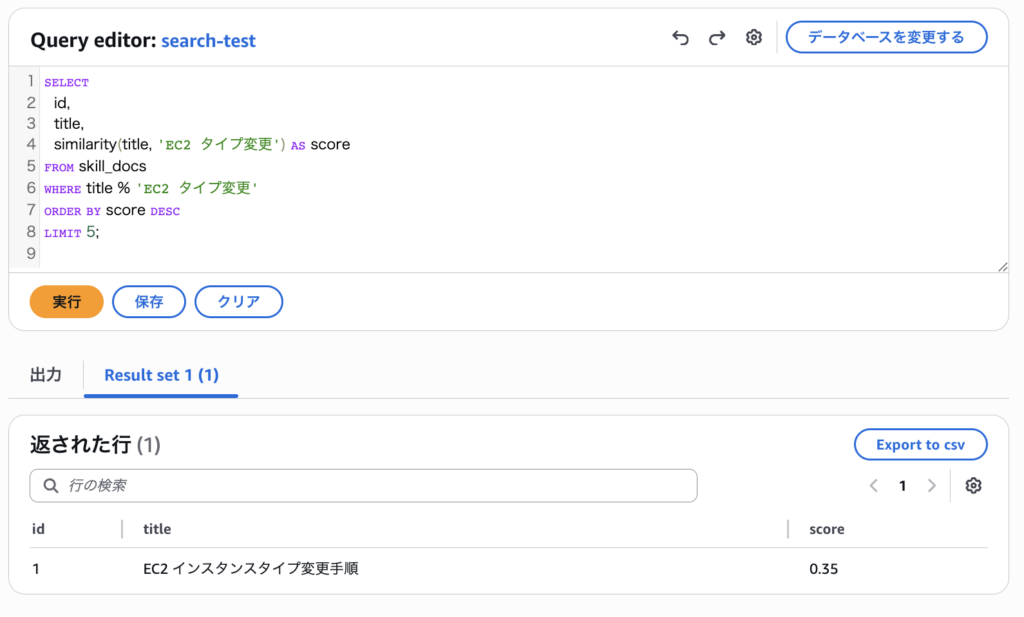
このクエリでは、「EC2 インスタンスタイプ変更手順」が高く評価されヒットし、「EC2 サイズ変更メモ」はヒットしませんでした。
これはpg_trgmの特性によるものです。
pg_trgmは「意味」ではなく「文字列の近さ」で判定するため、「タイプ変更」と「サイズ変更」は意味的には近くても、文字列としてはtrigramの共通部分が少なく、類似度が閾値(0.3)に届かなかったと考えられます。
pg_trgmの良いところは、完全一致でなくてもそこそこ近い語を拾えることです。「EC2 タイプ変更」と「EC2 インスタンスタイプ変更手順」は完全に同じ文字列ではありませんが、「EC2」「タイプ」「変更」といった共通のtrigramが多いため、高いスコアとなります。
ただし、意味的には近いけれど文字列が異なる文書は拾いにくいという弱点があります。今回のように「タイプ変更」と「サイズ変更」は、その典型例です。
ハイブリッド検索を試す
最後に、ベクトル検索とpg_trgmを組み合わせてみます。今回はシンプルに、両方のスコアを重み付き合算して総合スコアを出す形で試しました。重みはベクトル 0.7 : pg_trgm 0.3 としています。
WITH vector_search AS (
SELECT
id,
1 - (embedding <=> '[0.10, 0.20, 0.30, 0.39]'::vector) AS vector_score
FROM skill_docs
),
trgm_search AS (
SELECT
id,
GREATEST(
similarity(title, 'EC2 タイプ変更'),
similarity(content, 'EC2 タイプ変更')
) AS trgm_score
FROM skill_docs
)
SELECT
d.id,
d.title,
v.vector_score,
t.trgm_score,
(v.vector_score * 0.7 + t.trgm_score * 0.3) AS hybrid_score
FROM skill_docs d
JOIN vector_search v ON d.id = v.id
JOIN trgm_search t ON d.id = t.id
ORDER BY hybrid_score DESC
LIMIT 5;
このSQLは少し長いので、パートごとに解説します。
WITH句(CTE) を使って、まず「ベクトル検索のスコア」と「pg_trgm 検索のスコア」をそれぞれ別々に計算しています。WITH句は「一時的な名前付きテーブル」のようなもので、複雑なSQLを読みやすく分割できます。
vector_searchでは、先ほどと同じコサイン距離でベクトル検索のスコアを計算しています。
trgm_searchでは、titleとcontentそれぞれのsimilarityスコアを求め、GREATEST() で大きい方を採用しています。これにより、タイトルか本文のどちらかに検索語が近ければスコアが高くなります。
最後に、**(v.vector_score * 0.7 + t.trgm_score * 0.3) **で両方のスコアを重み付きで合算しています。ベクトルの重みを0.7、pg_trgm の重みを0.3 にしているので、「意味の近さをベースにしつつ、文字列の一致も加点する」というイメージです。この重みはユースケースに応じて調整してください。
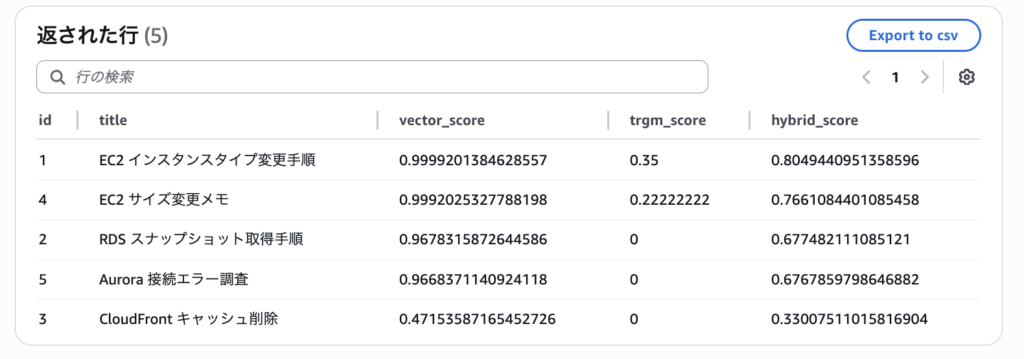
この方法だと、意味的に近い文書をベースにしつつ、文字列が近いものを少し優先して出力できます。実際に試してみると、「EC2 インスタンスタイプ変更手順」が最上位に来て、「EC2 サイズ変更メモ」がそれに続く形になりました。
ベクトル検索だけのときよりも、「意味は近くて語面もそれなりに合っている」文書を上に持ってきやすく、pg_trgmだけのときよりも言い換え表現に強い結果になりました。
運用手順書やナレッジ文書のように、意味検索だけでは拾い漏れが気になり、かといってキーワード検索だけでは取りこぼしが出るデータには、ハイブリッド検索の相性が良さそうです。
なお、重みの割合(0.7 : 0.3)はユースケースに応じて調整してください。キーワード重視ならpg_trgmの重みを上げるのも有効です。
まとめ
今回は、Aurora Serverless v2上でpgvectorとpg_trgmを組み合わせたハイブリッド検索を試してみました。改めてポイントをまとめます。
pgvectorだけの場合、意味的な言い換えも拾えますが、略語や固有名詞の正確な一致はコントロールが難しいです。
pg_trgmだけの場合、文字列が近いものを確実に拾えますが、意味的な言い換えには弱いです。
ハイブリッド検索なら、両方の強みを活かせます。意味的な近さとキーワード的な近さの両方を加味した検索ができるようになり、ナレッジ検索や手順書検索のような用途ではかなり相性が良さそうだと感じました。
Aurora Serverless v2についても、単に「簡単に作れる Aurora」というより、検索系のような波のあるワークロードに対して扱いやすい選択肢だと再認識しました。
今後試したいこととしては、Lambdaから検索API化した場合のレイテンシや、データ件数を増やした場合の挙動確認などを考えています。
最後まで読んでいただきありがとうございました!



元記事発行日: 2026年04月15日、最終更新日: 2026年04月15日













