AWS 障害情報の調べ方

コンピューターの世界に限ったわけではありませんが、業務に影響するさまざまな障害があります。
障害と言っても原因はさまざまで、もちろんAWSのようなクラウドサービスであっても例外なく障害発生の可能性はあり、頻繁ではありませんが実際に発生しています。
インフラの大規模な障害の発生頻度と比べた場合に、障害の原因として多いのはOSやアプリケーションのソフトウェアの問題や、クラウド環境では不可欠なネットワークが原因となっているケースもあります。
AWSで発生する障害は、大きく分けて以下となります。
- AWS インフラ側の要因
- 利用者側(OSやアプリケーション、ネットワーク設定など)の要因
- 上記以外(ネットワークインフラや、利用者側の機器)の要因
そこで、万が一障害が発生した場合に、AWSインフラが原因の大規模障害なのか、お客様環境の局所的な障害なのかを調べる手段についてご紹介します。
目次
AWS 障害情報 <公式>
Service Health Dashboard
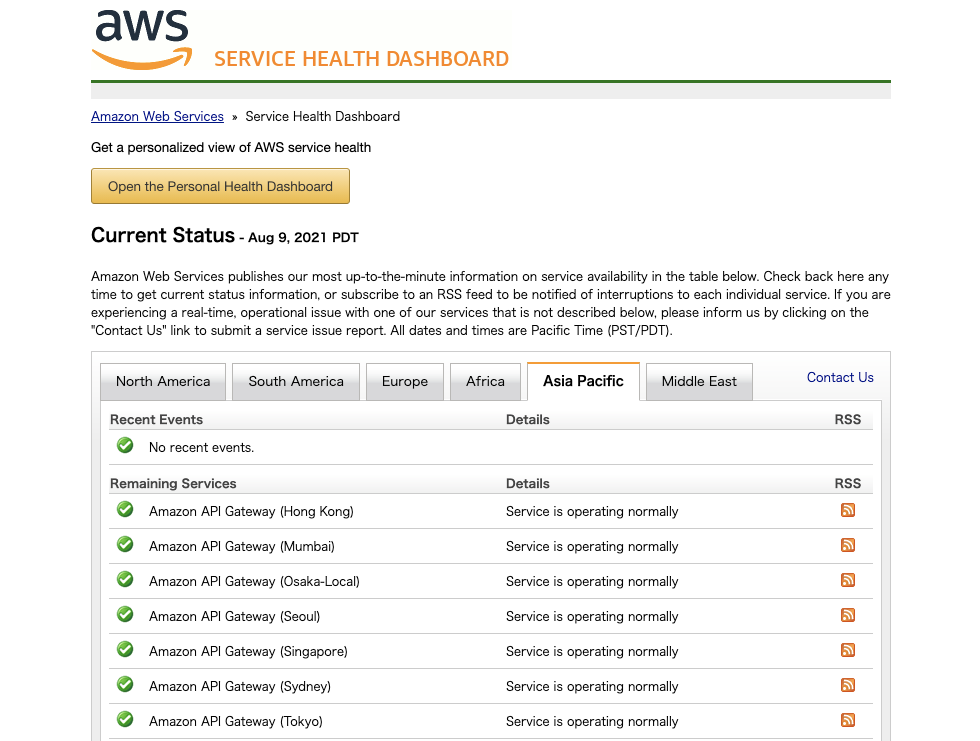
最初に見ていただきたいのは「Service Health Dashboard*1」です。AWSの全リージョンのサービス単位でのステータスが一覧表示されています。
サーバーに繋がらなくなった場合やWebページが表示されなくなったなどの障害が発生した場合には、まずここの障害情報をチェックしていただくことをお勧めします。大規模障害の場合はここに表示されます。
︙
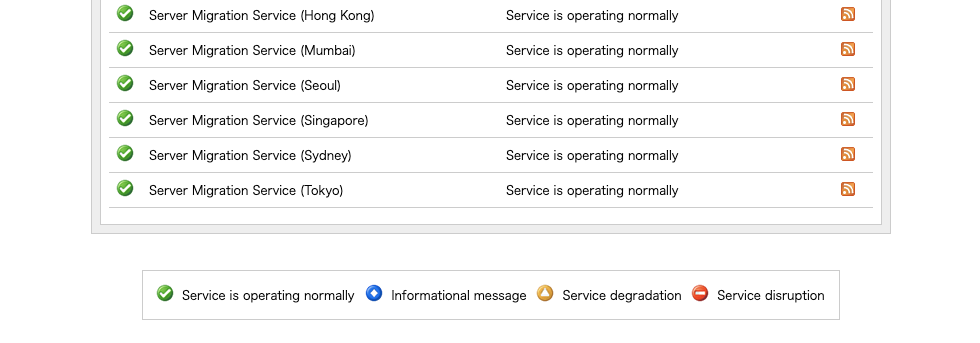
このページの上段の表が現時点のステータスとなっており、4種類のアイコンで表示されています。
| Service is operating normally | サービスは正常に稼働しています | |
| Informational message | エラー発生などのメッセージがあります | |
| Service degradation | サービスの提供品質に問題があります | |
| Service disruption | サービスが停止しています |
また、下段の表は過去のステータスが記載されており、約1年前までの状態や対応結果を確認することができます。
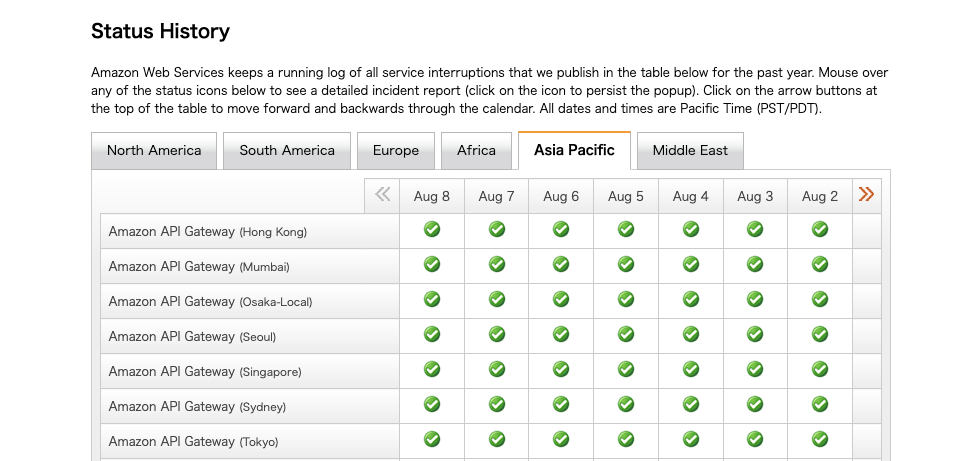
過去に発生した障害は、下記のような形で報告されています。(表示例)

「Service Health Dashboard」は、問題が発生しているかどうかを一覧で確認できますが、以下の注意点があります。
- 更新が若干遅い
- サービスが多いため、対象を見つけにくい場合がある
- 内容が英語で記載される(日付・時刻は太平洋時間 [PST/PDT] )
Twitter(ツイッター)
次にご確認いただきたいのが、公式Twitterです。
※ Twitterアカウントをお持ちでなくても、閲覧可能
障害の規模に関わらず、また「Service Health Dashboard」と比較して早く投稿されるようです。
AWS障害情報(全リージョン) (@awsstatusjp_all) | Twitter *2
AWS障害情報(東京リージョン関連のみ) (@awsstatusjp) | Twitter *3

AWS 障害情報 <非公式>
Downdetector(ダウンディテクター)*4
AWSの障害情報だけではありませんが、どの地域で障害が発生しているかをビジュアルで見ることができます。以下、提供元からの抜粋です。
ダウンディテクターは、テクノロジーでは予知できないネットサービスの接続障害をユーザーにいち早くお知らせする、言わばデジタル世界における天気予報のような情報サービスです。 ネットサービスの障害や中断などを予知することはできませんが、気象予報士が天気を予測するように、ダウンディテクターは障害の状況をネットユーザーに伝えることができます。
ダウンディテクターについて Downdetector
以下のように、過去24時間の障害報告件数と、地図上に障害件数の分布が表示されます。
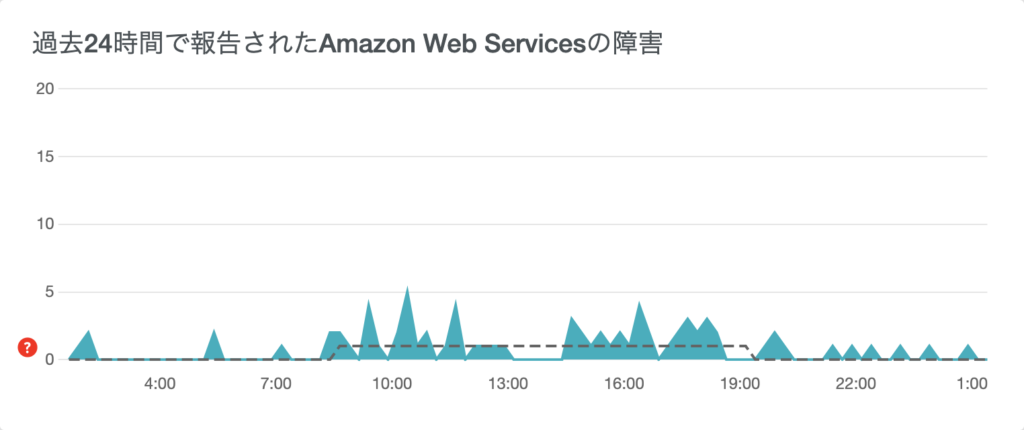
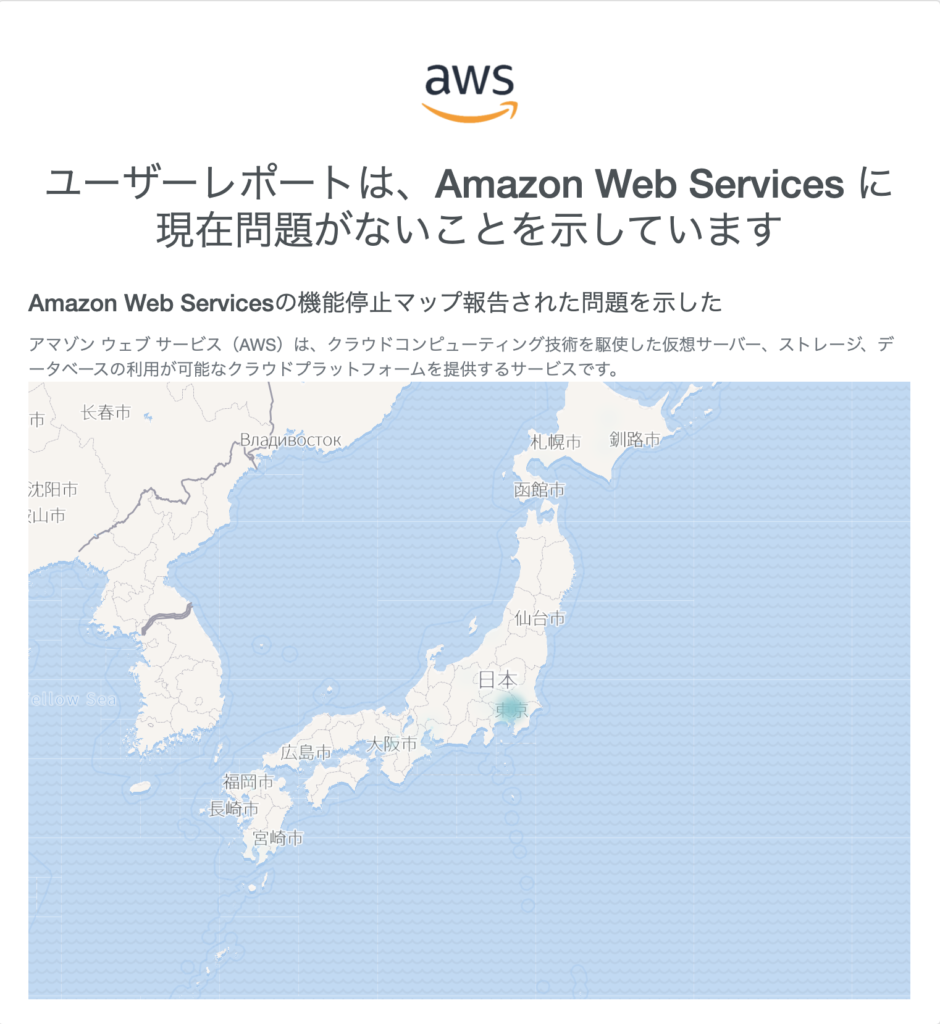
ご参考)Downdetector でチェックできるサービスの一部です。

弊社提供ツールで確認できる AWS 障害情報
Simple Dashboard(シンプルダッシュボード)
Simple Dashboardは、弊社の提供するツール(Webアプリ)です。
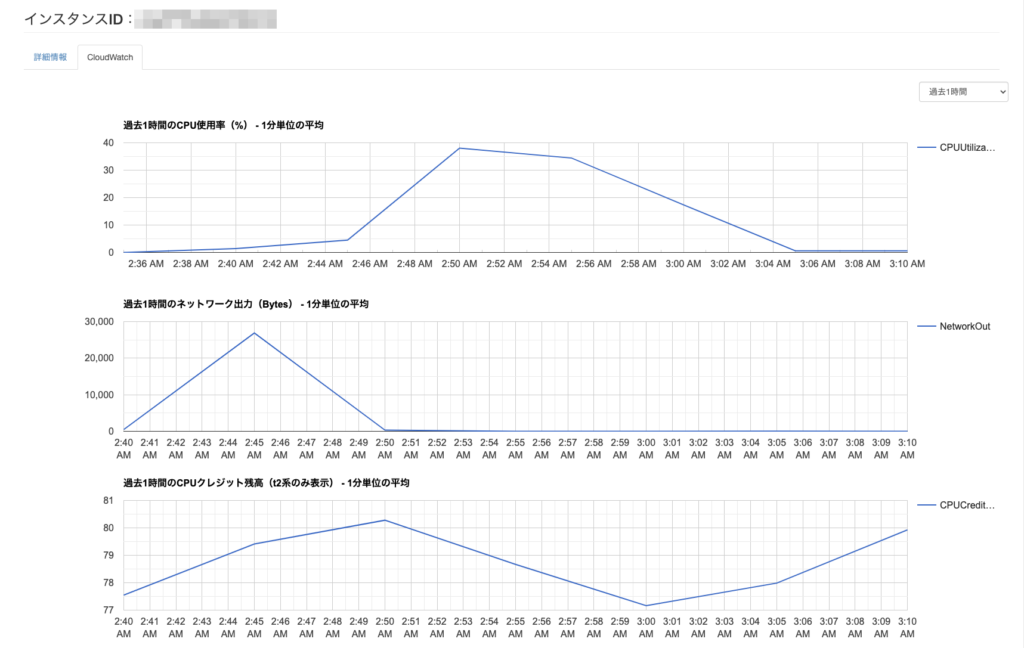
EC2インスタンスの表示例
- 詳細情報
- システム状態:AWS基盤(ハードウェア)
- インスタンス状態:オペレーティングシステム
- CPU使用率:直近1分または15分の平均値

- CloudWatch
- 過去1時間のCPU使用率 (%) - 1分単位の平均
- 過去1時間のネットワーク出力 (Bytes) - 1分単位の平均
- 過去1時間のCPUクレジット残高 (t2系のみ表示) - 1分単位の平均
- 過去1時間のステータスチェック (ハードウェア) - 1分単位の最大値
- 過去1時間のステータスチェック (OS) - 1分単位の最大値
RDSインスタンスの表示例
- 詳細情報
- RDSの状態:サービス全般
- CPU使用率:直近1分の平均値
- ディスク使用率:全容量に対する利用率 ※Auroraを除く
- DBコネクション数:直近1時間の推移

- CloudWatch
- 過去1時間のCPU使用率 (%) - 5分単位の平均
- 過去1時間のコネクション数 - 5分単位の平均
- 過去1時間のメモリ空き容量 (Bytes) - 5分単位の平均
AWS 障害情報の調べ方(まとめ)
cloud link など、サポート契約いただいているお客様で障害が発生してお困りの際は、弊社サポートまでご一報いただけましたら調査・対応させていただきます。
また、監視対象のインスタンスについては、障害の発生状況により弊社オペレータにアラートが通知されますので、より早い障害対応が可能です。
ご参考)AWS サービスレベルアグリーメント *5
リンク
*1 Service Health Dashboard
*2 AWS障害情報(全リージョン) (@awsstatusjp_all) | Twitter
*3 AWS障害情報(東京リージョン関連のみ) (@awsstatusjp) | Twitter
*4 Downdetector(ダウンディテクター)
*5 AWS サービスレベルアグリーメント



元記事発行日: 2022年06月05日、最終更新日: 2023年03月28日













