Terraform で再利用できる構成を考えてみた

こんにちは!11月に入り急激に寒くなって来ましたが、皆様如何お過ごしでしょうか?
こう寒いとダラケてサボりたくなってしまう。。。そんな時は業務を自動化して楽をするのが一番です!
今回は、クラウドインフラのコード化(Infrastructure as Code)ツールとしてTerraformをAWS環境で活用できないか検討してみました。
目次
なぜTerraformか
クラウドリソースを作成・管理する方法はいくつかありますが、AWS CDKやAWS SAMで行ったり、AWS CLIでコマンドを実行したり、AWS CloudFormationのテンプレートを使ったりする方法があります。しかし、今回私はTerraformを選択しました。
なぜTerraformを選んだのか?それは再利用性と柔軟性です。もちろんベタ書きのコードでも構築は可能ですが、将来的に似たような構成を別のプロジェクトで再利用したり、環境(開発・テスト・本番など)ごとに設定を切り替えたりするためには、きちんとした構成を考える必要があります。
また、弊社ではAzureを取り扱っていることもあり、マルチクラウドに対応しているかどうかも大きなポイントでした。
代表的、かつ、公式のIaCツールであるAWS CloudFormationと比較してTerraformの優位点についても触れておきたいと思います。
- マルチクラウド対応: TerraformはAWSだけでなく、Azure、GCP、その他多くのクラウドプロバイダーに対応しています。将来的にマルチクラウド環境になった場合でも、同じツールで管理できるのは大きな利点です。
- モジュール化が容易: Terraformはコードの再利用性を高めるためのモジュール構造が洗練されており、使いやすいです。
- 状態管理の柔軟性: tfstateファイルをS3やTerraform Cloudなど、さまざまな場所に保存できます。
- HCLの可読性: Terraformで使用するHashiCorp Configuration Language (HCL) は可読性が高く、JSONより直感的に記述できます。
- 豊富なプロバイダーエコシステム: 公式・コミュニティの両方から多くのプロバイダーが提供されています。

Terraformの構成を検討してみた
それでは、実際に検討した結果に作成したプロジェクト構成について見ていきましょう。
それでは、実際のプロジェクト構成について見ていきましょう。
Terraform構成の説明
プロジェクトフォルダの概要
今回作成したプロジェクトは、再利用性と管理のしやすさを考慮して設計しました。主に以下のディレクトリ構造になっています:
terraform-pj/
├── environments/
│ ├── .terraform.lock.hcl
│ ├── ec2.tf
│ ├── provider.tf
│ ├── subnet.tf
│ ├── variables.tf
│ └── vpc.tf
└── modules/
├── compute/
│ └── ec2/
│ ├── main.tf
│ ├── outputs.tf
│ └── variables.tf
└── network/
├── subnet/
│ ├── main.tf
│ ├── outputs.tf
│ └── variables.tf
└── vpc/
├── main.tf
├── outputs.tf
└── variables.tf
以下は、このプロジェクト構造とモジュール間の関係を示す図です。
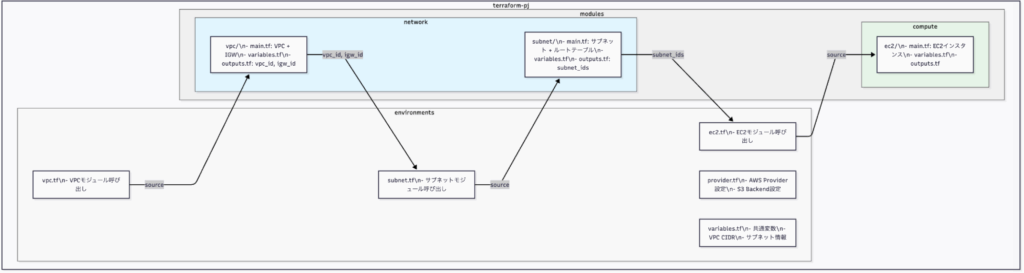
この構成はモジュールベースのアプローチを採用しており、modulesとenviromentsの2つの主要なディレクトリがあります。それぞれの役割と関係性について詳しく説明します。
modulesとenviromentsの説明と関係性
modules ディレクトリ
modulesディレクトリには、再利用可能なインフラコンポーネントのテンプレートが格納されています。これらは汎用的に作られており、さまざまな環境で使い回すことができます。各モジュールは特定のリソースタイプ(VPC、サブネット、EC2など)に焦点を当てています。
このプロジェクトでは、以下のモジュールを作成しました:
- network/vpc: VPCとインターネットゲートウェイを作成するためのモジュール
- network/subnet: パブリックサブネットとプライベートサブネットを作成するためのモジュール
- compute/ec2: EC2インスタンスを作成するためのモジュール
各モジュールは通常、3つの重要なファイルから構成されています:
- main.tf: リソースの定義を記述
- variables.tf: モジュールに渡す変数の定義
- outputs.tf: モジュールから出力する値の定義
例えば、VPCモジュールのmain.tfは次のようになっています。
resource "aws_vpc" "vpc" {
cidr_block = var.cidr
instance_tenancy = "default"
enable_dns_support = "true"
enable_dns_hostnames = "true"
tags = {
Name = "${var.suffix}-vpc"
}
}
resource "aws_internet_gateway" "igw" {
vpc_id = aws_vpc.vpc.id
tags = {
Name = "${var.suffix}-igw"
}
}
非常にシンプルですが、CIDRブロックやタグの名前などを変数として受け取るため、様々な環境で再利用できます。
enviroments ディレクトリ
enviromentsディレクトリには、特定の環境(今回の場合は一つの環境)のための具体的な設定が含まれています。このディレクトリ内のファイルは、modulesディレクトリ内のモジュールを呼び出し、特定のパラメータを渡します。
例えば、vpc.tfファイルでは、次のようにVPCモジュールを呼び出しています:
module "vpc" {
source = "../modules/network/vpc"
suffix = var.suffix
cidr = var.cidr
}
ここでsourceはモジュールの場所を示し、suffixとcidrは変数として渡されています。これらの変数はvariables.tfファイルで定義されています:
variable "suffix" {
type = string
default = "kotera"
}
variable "cidr" {
type = string
default = "172.16.0.0/16"
}
また、provider.tfファイルにはAWSプロバイダーの設定と、Terraformの状態を保存するためのバックエンド設定が含まれています:
provider "aws" {
region = "ap-northeast-1"
profile = "xxxxxx-xxxxxxx"
assume_role {
role_arn = "arn:aws:iam::xxxxxxxxx:role/tf-role"
}
}
terraform {
required_version = ">=1.3.8"
backend "s3" {
bucket = "tfstate-xxxxxx"
key = "key.tfstate"
region = "ap-northeast-1"
profile = "xxxxxx-xxxxxxx"
role_arn = "arn:aws:iam::xxxxxxxxx:role/tf-role"
}
required_providers {
aws = {
source = "hashicorp/aws"
version = ">=4.17.0"
}
}
}
※認証情報部分は伏せ字にしています。
モジュールの関係性とデータフロー
モジュール間の関係性を理解することは重要です。例えば、サブネットモジュールはVPCモジュールの出力値(VPC ID、IGW ID)を入力として使用します:
module "subnet" {
source = "../modules/network/subnet"
vpc_id = module.vpc.vpc_id
subnets_info = var.subnets_info
suffix = var.suffix
igw_id = module.vpc.igw_id
}
そして、EC2モジュールはサブネットモジュールの出力値(サブネットID)を入力として使用します:
module "app1" {
source = "../modules/compute/ec2"
subnet_id = module.subnet.private_subnet_ids["172.16.3.0/24"]
suffix = var.suffix
instancetype = "t3.micro"
server_name = "app-server-01"
ami = data.aws_ami.amzlinux2.id
}
このように、モジュール間でデータを受け渡しすることで、リソース間の依存関係を適切に管理しています。
出来上がった構成図
以下は、今回のTerraformプロジェクトで構築されるAWSリソースの概略図です。
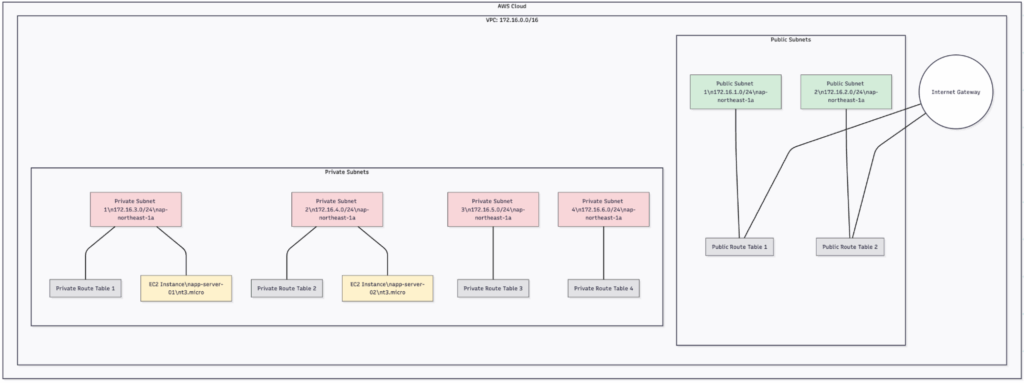
一般的に作成するであろう構成で考えてみました。
この構成では、2つのパブリックサブネットと4つのプライベートサブネットを持つVPCを作成しています。パブリックサブネットにはインターネットゲートウェイが接続されており、プライベートサブネットには2つのEC2インスタンス(app-server-01とapp-server-02)が配置されています。
コードの詳細解説
変数の定義と利用
変数を使うことで、環境ごとに異なる設定を簡単に変更できるようになります。例えば、今回の実装ではsuffix変数を定義して、すべてのリソースの名前に共通の接尾辞をつけています:
variable "suffix" {
type = string
default = "kotera"
}
この変数は、VPCやサブネットなどの名前に使われています:
tags = {
Name = "${var.suffix}-vpc"
}
また、サブネット情報は複雑なマップ型の変数で定義されています:
variable "subnets_info" {
default = {
public_subnets = [
{
prefixes = "172.16.1.0/24",
zone = "ap-northeast-1a"
},
{
prefixes = "172.16.2.0/24",
zone = "ap-northeast-1a"
}
],
private_subnets = [
{
prefixes = "172.16.3.0/24",
zone = "ap-northeast-1a"
},
// ...他のプライベートサブネット...
]
}
}
これにより、サブネットの追加や削除が簡単に行えます。
ループと動的リソース作成
Terraformのfor_eachを使用して、同じ種類のリソースを複数作成しています。例えば、サブネットモジュールでは次のようにfor_eachを使用しています:
resource "aws_subnet" "public_subnet" {
for_each = { for idx, subnet in var.subnets_info.public_subnets : idx => subnet }
vpc_id = var.vpc_id
cidr_block = each.value.prefixes
availability_zone = each.value.zone
tags = {
Name = "${var.suffix}-public-subnet-${each.key + 1}"
}
}
これにより、var.subnets_info.public_subnetsリストの各要素に対して1つのサブネットが作成されます。
状態管理
Terraformの状態ファイル(tfstate)は、S3バケットに保存するように設定しています:
backend "s3" {
bucket = "tfstate-xxxxxx"
key = "key.tfstate"
region = "ap-northeast-1"
profile = "xxxxxx-xxxxxxx"
role_arn = "arn:aws:iam::xxxxxxxxx:role/XXXX"
}
これにより、チームメンバー間で状態を共有でき、同時編集による競合を防ぐことができます。
データソースの活用
AMI IDのような変動する値は、データソースを使って動的に取得しています:
data "aws_ami" "amzlinux2" {
most_recent = true
owners = ["amazon"]
filter {
name = "name"
values = ["amzn2-ami-hvm-*-x86_64-gp2"]
}
}
これにより、常に最新のAMIを使用することができ、AMI IDが変更されても手動で更新する必要がなくなります。
最後に
今回のプロジェクトでは、AWSリソースをTerraformで管理する方法について見てきました。モジュール化された構造を採用することで、コードの再利用性が高まり、複数の環境や将来のプロジェクトでも活用できるようになりました。
特に以下のポイントが重要だと感じました:
- モジュール化: リソースをモジュール化することで再利用性が高まり、コードの重複を避けられます。
- 変数の活用: 環境ごとに異なる値を変数として定義することで、柔軟に対応できます。
- 状態管理: S3のようなリモートバックエンドを使用して状態を管理することで、チーム開発が円滑になります。
- データソース: 動的な値はデータソースを使って取得することで、手動更新の手間を省きます。
マルチクラウド環境が増えている現代において、Terraformのようなクラウドに依存しないIaCツールの重要性はますます高まっています。AWSだけでなく、Azure、GCPなど他のクラウドプロバイダーを使う場合でも、Terraformなら同じ構文と概念で管理できるのは大きなメリットです。
みなさんもTerraformを使って、インフラ構築を自動化し、効率的な運用を実現してみてはいかがでしょうか?最初は学習曲線が急かもしれませんが、一度マスターすれば開発スピードが格段に向上し、ヒューマンエラーも減らせます。最近ではAIが自動生成してくれますが、AIが作成したものをレビューする力は絶対に必要ですので、AIを利用しながら学び、マスターした後はレビュアーの立ち位置でAIをこき使うのがいいかと思います。
ぜひ楽しみながら挑戦してみてください!
それでは、Happy Terraforming!



元記事発行日: 2025年12月03日、最終更新日: 2025年11月28日













