AWS Application Load Balancer (ALB) 使用時の注意点

弊社へのよくあるお問い合わせの1つに、Application Load Balancer (ALB) で冗長化した構成に関するお問い合わせが挙げられます。
Application Load Balancer (ALB) は AWS マネージドのロードバランサーのため、利用者自身で管理する手間を減らせるのですが、構築時に注意すべき項目がいくつかあります。
そこで、本ブログでは弊社にお問い合わせいただくことの多い、注意すべき項目についてご紹介いたします!
目次
AWS Application Load Balancer (ALB) の注意点 ─
ターゲットグループのヘルスチェック
Application Load Balancer (ALB) のターゲットサーバーのヘルスステータスは、“healthy”の状態を正とすることを推奨いたします。
「そんなこと、言われなくても分かるわ!」と思われるかもしれませんが、Application Load Balancer (ALB) の仕様にちょっとした落とし穴があるのです。。
その落とし穴について以下の3つのケースを通してご紹介いたします!
<ご紹介する AWS 構成例>
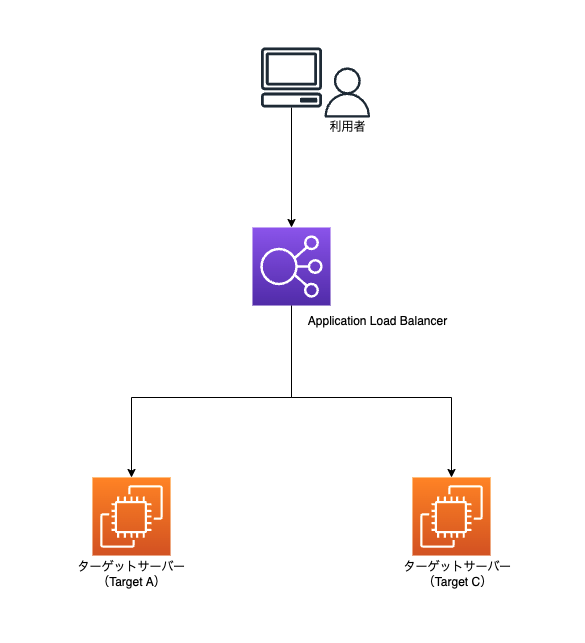
各ターゲットサーバーには Apache をインストール後、「/var/www/html」配下に以下のような index.html をそれぞれ配置しております。
<html lang="ja">
<head>
<meta charset="utf-8">
<title>test-page</title>
</head>
<body>
<h1>Hello world! This is Target A (Target C) !</h1>
</body>
</html>
ロードバランシングアルゴリズムはラウンドロビンで維持設定(スティッキーセッション)は無効です。
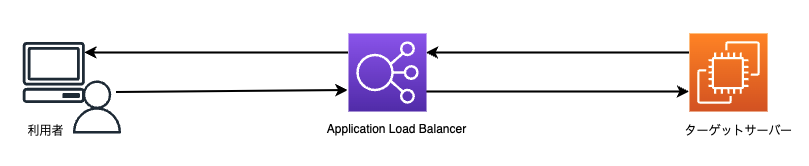
ケース1| 両ターゲットサーバー共にヘルスステータスが“healthy”

Application Load Balancer (ALB) の DNS 名でサイト表示してみると。。
[1回目の接続]

[2回目の接続]

しっかりと振り分けられていますね!
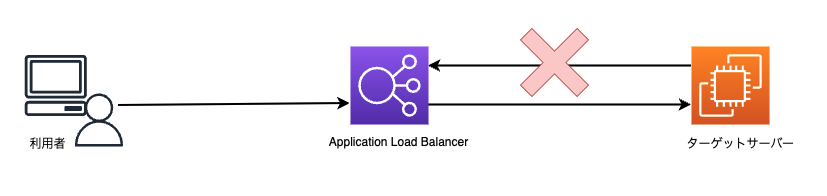
ケース2| 片方のターゲットサーバーのヘルスステータスを“unhealthy”に変更

(今回は、Apache を意図的に停止します)
Application Load Balancer (ALB) の DNS 名でサイト表示してみると。。
[1回目の接続]
[2回目の接続]
“unhealthy”のターゲットサーバー(Apache が停止しているターゲットサーバー)には振り分けられなくなりました。
ケース3| 両ターゲットサーバー共にヘルスステータスが“unhealthy”

(今回は Application Load Balancer (ALB) のヘルスチェックパスを両ターゲットサーバーに存在しないパスに変更し“unhealthy”にします)
どうなるでしょうか。。
[1回目の接続]
[2回目の接続]
── ?!?!?!?!?!
なんと、振り分けられてしまいました!
「“unhealthy”だし振り分けられないんじゃないの?」と思った方もいるのではないでしょうか?
例えば、すべてのターゲットサーバーのヘルスステータスが“unhealthy”の状態で運用してしまっていたら、障害が発生しているターゲットサーバーにも通信が振り分けられてしまうことになります。
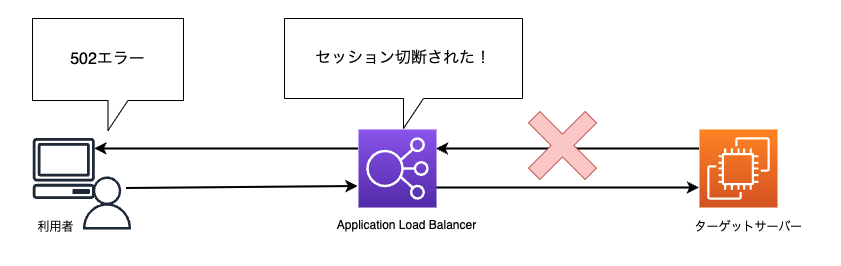
試しに、両ターゲットサーバー共にヘルスステータスが“unhealthy”の状態で、ケース2と同様に片方のターゲットインスタンスの Apache を意図的に停止してみます。
[1回目の接続]

[2回目の接続]
このように、Apache が停止しているターゲットサーバーにも振り分けられてしまい、「502 Bad Gateway」が表示されてしまいます。
利用者はページが表示されるときもあれば、表示されないときもあることになります。
これが落とし穴です!
まとめると以下の挙動になります。
- すべてのターゲットサーバーのヘルスステータスが“healthy”
→ すべてのターゲットサーバーに振り分けられる。
- 一部のターゲットサーバーのヘルスステータスが“unhealthy”
→ ヘルスステータスが“healthy”のターゲットサーバーにのみ振り分けられる。
- すべてのターゲットサーバーのヘルスステータスが“unhealthy”
→ すべてのターゲットサーバーに振り分けられる。
運用開始前にはターゲットサーバーのヘルスステータスの状態確認をお忘れなく!
AWS Application Load Balancer (ALB) の注意点 ─
ターゲットサーバーの設定
Application Load Balancer (ALB) のターゲットサーバーに Apache や NGINX を使用する際は AWS 公式サイト*1 で紹介されている設定をご確認いただくことを推奨いたします。
中でも、502エラーが表示された際の原因についてお問い合わせいただくことが多いです。AWS 基盤側の問題である場合ももちろんあるのですが、502エラーが表示される場合は、以下の設定を見直していただくことで解決することがほとんどですので今回ご紹介させていただきます。
- Application Load Balancer (ALB) のアイドルタイムアウトの値
- ターゲットサーバーのキープアライブの設定
- ターゲットサーバーのキープアライブタイムアウトの設定
キープアライブ (Apache の KeepAlive、NGINX の keepalive_disable)
CPU 使用率を削減し、応答時間を改善するには、キープアライブをオンにします。キープアライブをオンにすると、ロードバランサーで、HTTP リクエストの度に新しい TCP 接続を確立する必要がありません。キープアライブタイムアウト (Apache の KeepAliveTimeout、NGINX の keepalive_timeout)
キープアライブオプションが有効になっている場合は、ロードバランサーのアイドルタイムアウトよりも長いキープアライブタイムアウトを選択します。
引用元:AWS公式サイト - ELB のバックエンドサーバーとして Apache または NGINX を使用するための最適な設定を教えてください。
Application Load Balancer (ALB) はアイドルタイムアウトで設定した時間が経過するまでデータが送受信されなかった場合、接続を閉じます。(2022年5月13日時点、デフォルト値60秒)
ターゲットサーバーのキープアライブタイムアウトが、Application Load Balancer (ALB) のアイドルタイムアウトの値より小さい場合、Application Load Balancer (ALB) がセッションを維持している期間中であってもターゲットサーバーがセッションを切断するような動きとなります。
※あくまで一例です。詳細は AWS 公式サイト*2 をご確認ください。
また、1回のセッション中に Application Load Balancer (ALB) がターゲットサーバーからのレスポンスを長時間待つ必要がある処理を実施する場合にも注意点がございます。
ファイルアップロード等の長いオペレーションを実施する場合、オペレーションの完了までセッションを維持し続ける必要があります。
前述の通り、Application Load Balancer (ALB) はアイドルタイムアウトで設定した時間が経過するまでデータが送受信されなかった場合、接続を閉じてしまいます。そのため、Application Load Balancer (ALB) のアイドルタイムアウトで設定した時間が経過するまでに、少なくとも1バイトのデータを送信し、アイドルタイムアウトを延長する必要がございます。
AWS Application Load Balancer (ALB) の注意点 ─ まとめ
Application Load Balancer (ALB) は利用者自身でのロードバランサーの管理の手間を減らせる大変便利なサービスですが、マネージドなサービスであるが故に、不適切な設定をしてしまうと障害時の原因調査に膨大な時間を要する可能性があります。
適切な設定をして、管理の手間や障害時の調査時間を最小限にしたいですね!
「Application Load Balancer (ALB) のヘルスチェックステータスの変化を検知して連絡して欲しい!」等のご要望がある方は、ぜひ弊社までご相談ください。
*1 ELB のバックエンドサーバーとして Apache または NGINX を使用するための最適な設定を教えてください。
*2 Application Load Balancer のトラブルシューティング



元記事発行日: 2022年07月12日、最終更新日: 2024年02月28日













